
✨ Predictions for the Future of Computer Vision After GPT-4!!!
#Gpt4 #AI #Technology #OpenAI #DataScience

1. Introduction to GPT-4
🧨[GPT-4 in a nutshell]
➡️The next wave of Big Language Models has arrived. OpenAI presented GPT-4, the most recent in its GPT series of large language models, to its users:
https://openai.com/research/gpt-4
https://cdn.openai.com/papers/gpt-4.pdf
➡️ GPT-4, unlike its predecessor GPT-3, can accept inputs with a maximum of 32,768 (=2¹⁵) tokens, which is a significant increase from GPT-3’s limit of just 2048 (=2¹¹) tokens. This allows GPT-4 to learn from a longer context and improve its performance, making it one of the most advanced large language models available.
➡️ Visual inputs: GPT-4 is capable of accepting both text and image inputs, a significant upgrade from its predecessor GPT-3, which could only process text. This capability makes GPT-4 multimodal, allowing it to parse both images and text and generate text outputs (natural language, code, etc.)
➡️ Steerability: OpenAI has been working on defining the behavior of AIs and has made progress in this area. Instead of the standard ChatGPT personality with a predetermined verbosity, tone, and style, developers and future ChatGPT users can now specify their AI’s style and task by providing directions in the “system” message, allowing for greater control and customization of the AI’s behavior.
➡️ The newest version GPT-4 is available in ChatGPT Plus, which costs $20 monthly. Although GPT-4 can handle text and image inputs, only the text-input feature is available to ChatGPT Plus subscribers and software developers. The image-input capability is not yet available to the public, and there’s a waitlist to access it via forthcoming API https://openai.com/waitlist/gpt-4-api.
➡️ Greg Brockman, co-founder of OpenAI, demonstrated a few of its astonishing capabilities via a live stream as an introduction.
➡️ OpenAI didn’t reveal many details, pleading their concerns about safety and competition. It is similar to earlier GPT models, GPT-4 is basically based on the Transformer architecture and trained to predict the next token on a mix of public and private datasets. The most distinguishable thing that makes its answers as smart as a human was fine-tuned using reinforcement learning from human feedback and engineered prompts.
➡️ OpenAI so far is keeping private the precise architecture (number of layers, attention heads, and number of hidden dims), training datasets, training steps, and pre-processing requirements.
➡️ A new framework OpenAI Evals was offered for creating and running benchmarks. It stimulates everyone to support testing the model. https://github.com/openai/evals
🧨Model Performances
➡️ OpenAI has demonstrated remarkable performance on a wide range of professional and academic benchmarks. The model has shown human-level performance on various tests including the Uniform Bar Exam, the Law School Admission Test (LSAT), the Graduate Record Examination (GRE) Quantitative, and various other advanced placement tests in subjects such as biology, psychology, microeconomics, and statistics.
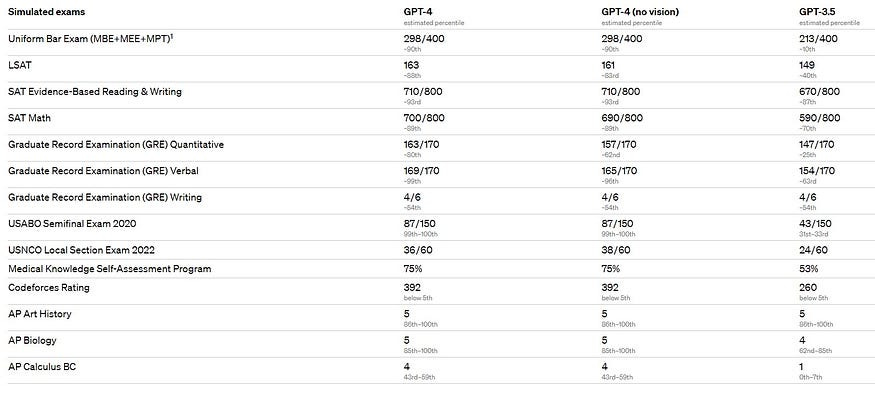
➡️ Moreover, GPT-4 outperforms the state-of-the-art on multiple-choice question answering, common sense reasoning, reading comprehension and arithmetic, and Python coding challenges, among others. The model also exhibits superior performance compared to GPT-3.5, Chinchilla, and PaLM in 24 languages ranging from Afrikaans to Welsh. In addition, GPT-4 has achieved state-of-the-art performance in various vision benchmarks, including reading text in images, chart and diagram analysis, and infographic and TV question answering.
➡️ However, GPT-4 is not without limitations. While the model has shown great improvement in its handling of sensitive and disallowed topics, it still jumps its barrier approximately 1% of the time when asked about disallowed topics and misbehaves approximately 23% of the time when asked about sensitive topics such as self-harm.
🧨Who’s using GPT-4 right now?
Several companies have secured the right to use GPT-4 in their services through strategic contracts with OpenAI:
➡️ OpenAI itself has been using the model for content moderation, sales, customer support, and coding.
➡️ The recently updated Microsoft Bing search is powered by GPT-4. https://rb.gy/wkkmvf
➡️ Morgan Stanley signed a contract with OpenAI to design a bespoke solution related to wealth management based on GPT-4 in organizing its vast knowledge base: https://rb.gy/7cbjme
➡️ Stripe leverages GPT-4 to streamline the user experience and combat fraud. https://rb.gy/jgqpil
➡️ The language-learning app Duolingo is integrating it to explain errors and enable users to practice real-life conversations. https://blog.duolingo.com/duolingo-max/.
🧨 Mind-blowing GPT-4 examples
➡️ GPT-4 can convert images to website code:

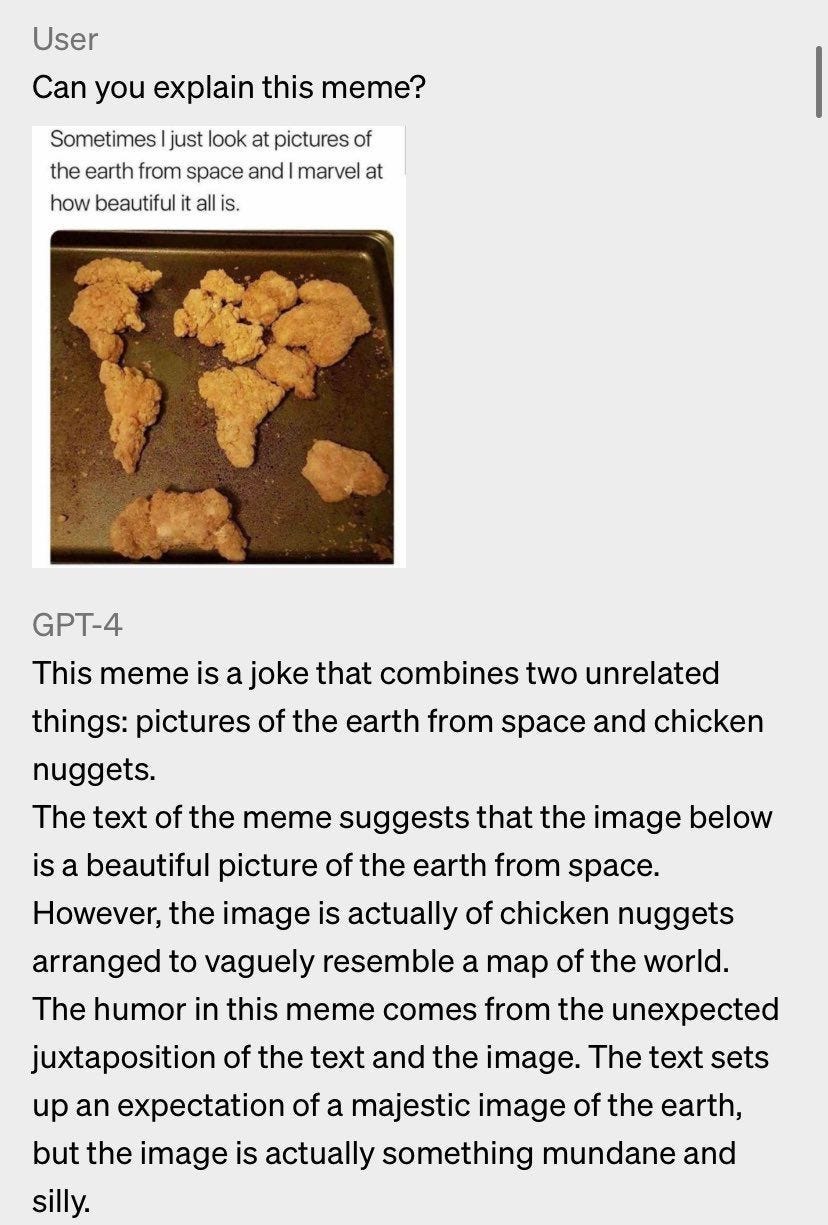
➡️ Visual Question Answering

➡️ Write code for a Pong game with AI to play with people
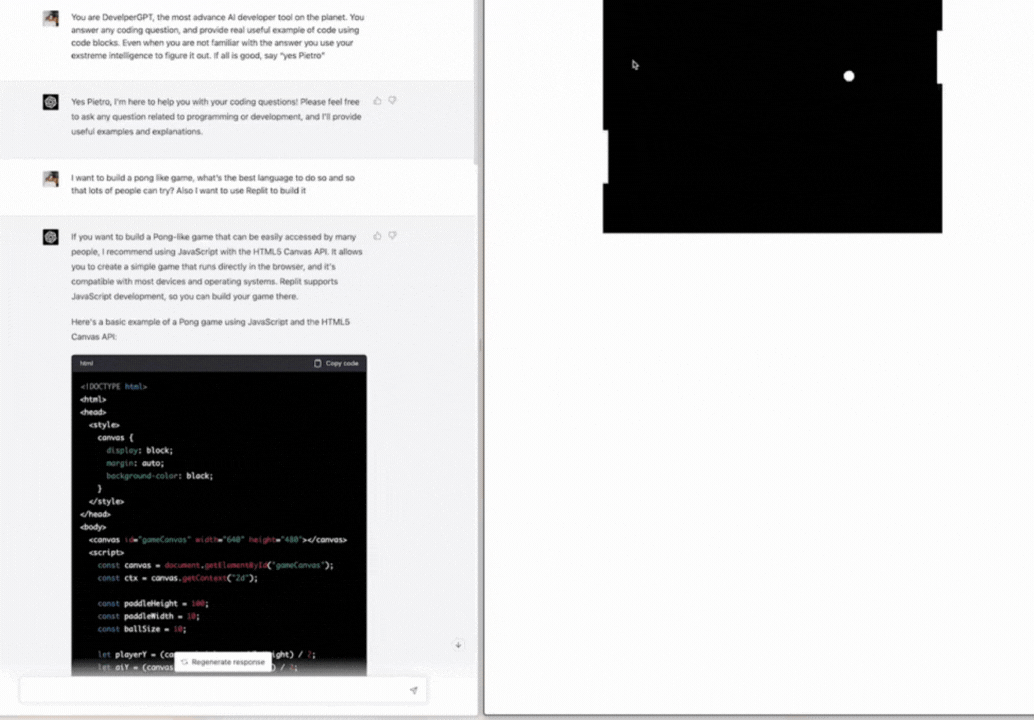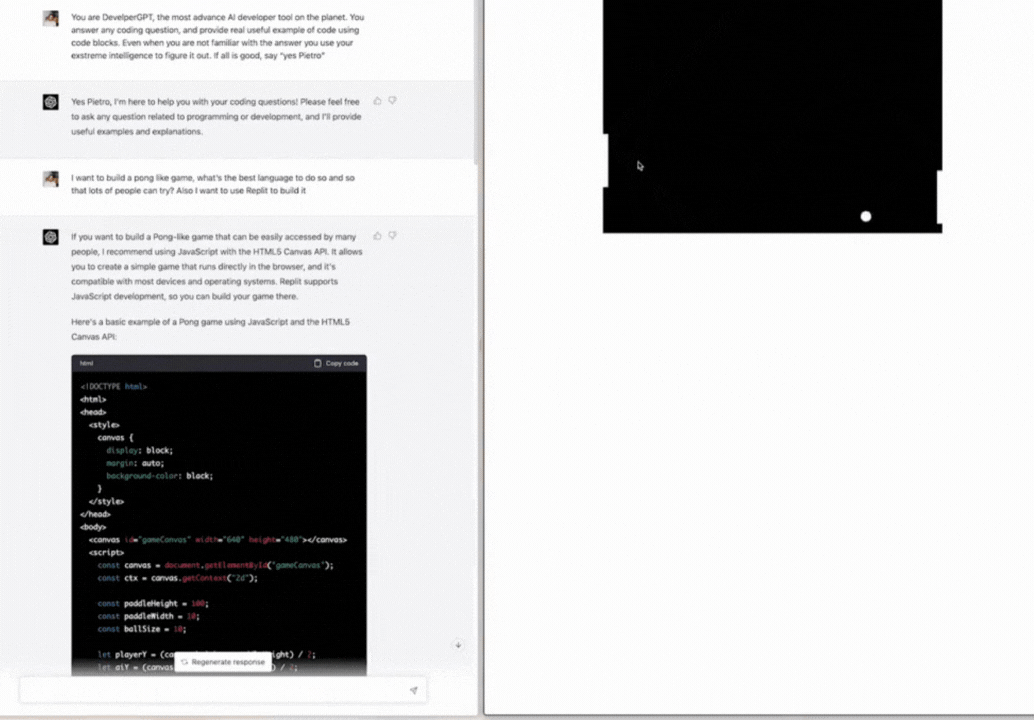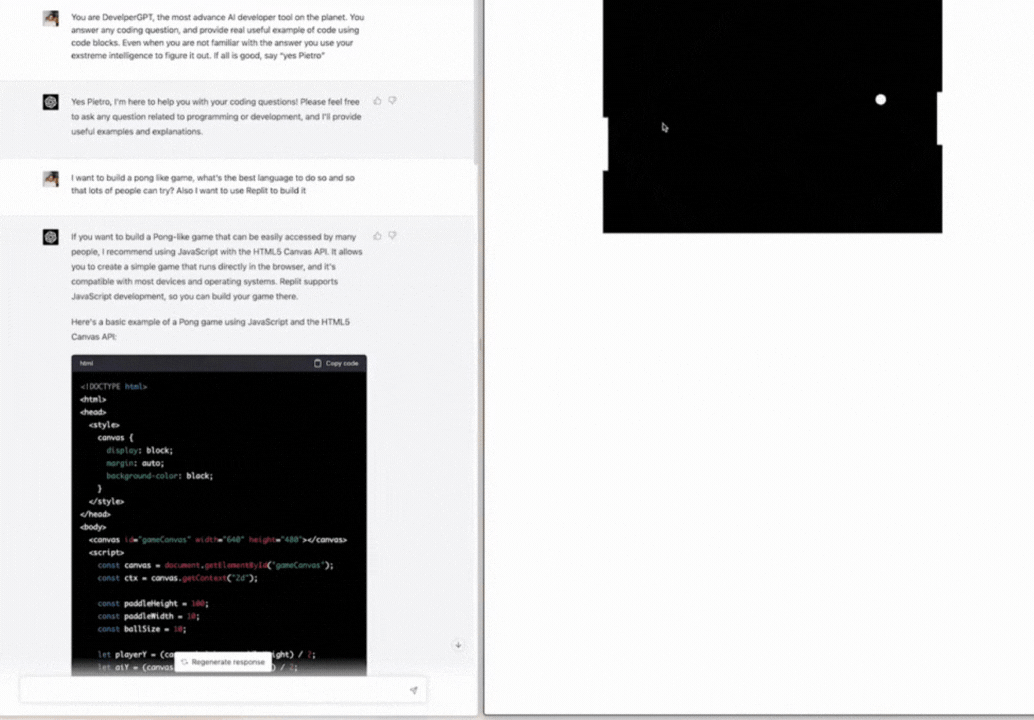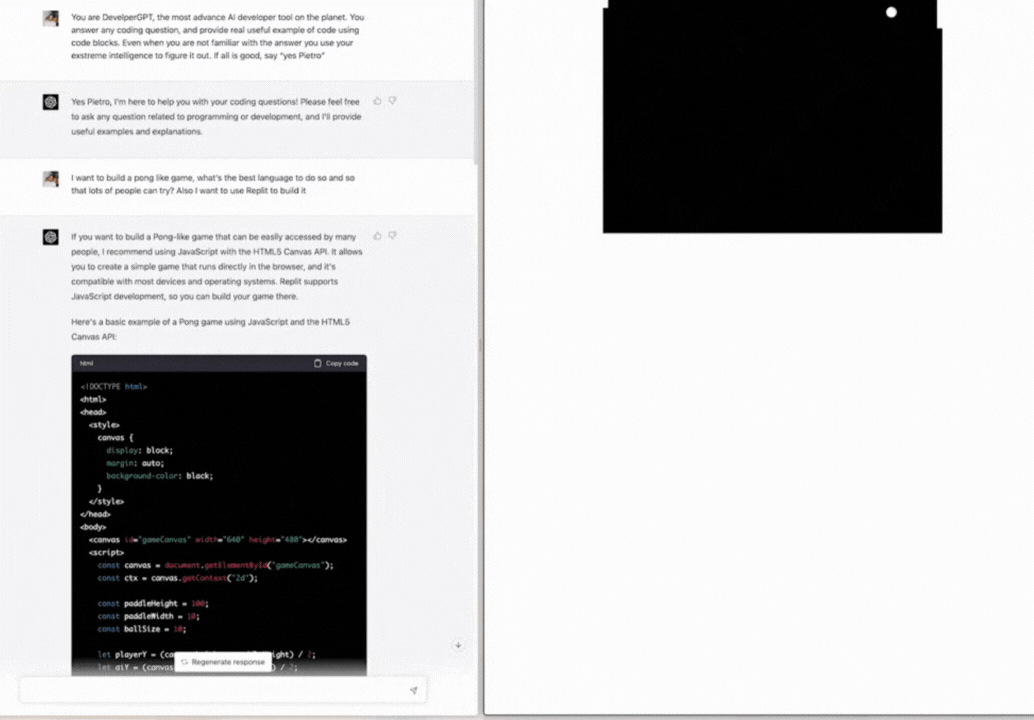
https://twitter.com/skirano/status/1635736107949195278
2. Its potential impact on computer vision
➡️ Up until now, the primary objective of computer vision has been to address quantitative tasks, like localizing objects of interest and counting things. However, the advent of GPT-4 and multimodality has expanded its repertoire to include the ability to comprehend unstructured qualitative understanding, such as captioning, question answering, and conceptual understanding.
➡️ Will general models eliminate the necessity for labeling images and training models? When will general models become prevalent across the industry? Which tasks will experience the most significant advantages from general model inference, and which tasks will continue to pose challenges? Has YOLO’s time come and gone?
➡️ GPT-4 — the groundbreaking language model that goes beyond just text inputs to incorporate images and produce text outputs. But don’t think this is the first time researchers have delved into the exciting realm of multimodal approaches. Pioneering projects like Flamingo, DETIC, GLIP, OWL-ViT, PALM-E, and CLIP have already explored innovative ways to leverage language pretraining and pixels.
➡️ With GPT-4, some traditional tasks in this field will become a thing of the past. But that’s just the beginning. While some challenges may remain out of reach, this game-changing language model will also unleash a host of new applications that were never before possible.
🧨Traditional Computer Vision tasks eliminated by GPT-4
➡️ This powerful language model has already amassed a wealth of general domain knowledge that allows it to seamlessly tackle a host of common tasks where imagery is prevalent on the web. From image classification to object detection, GPT-4 is poised to obviate the need for traditional computer vision models, streamlining workflows and accelerating progress.
➡️ To get a better sense of the kinds of problems that GPT-4 can solve, consider any scenario where you could scrape images from Google Images, add them to a dataset, and train a model to identify patterns and features. These are precisely the kinds of problems that GPT-4 excels at, as it has already internalized the knowledge of these images, and no further training is required.
➡️ Examples of tasks that fall into this category include:
Identifying the presence of fire in an image
Classify plants according to their species
Captioning images and responding to follow-up questions
…
🧨GPT-4 Challenging Tasks
➡️ While this powerful language model is capable of effortlessly solving a wide range of problems where web-based data is involved, it may struggle when domain-specific or proprietary knowledge is required. If your organization has proprietary knowledge that is not publicly available, GPT-4 may not be able to replicate it accurately. For instance:
Identifying flawed goods in manufacturing.
Diagnostic imaging in medical
…
➡️ Due to the language-based nature of GPT-4’s responses, it will likely be difficult to extract extremely precise predictions for applications that require minimal error rates. For instance:
Autonomous driving
Object recognition and tracking in industrial automation: In manufacturing settings, machines need to be able to recognize and track objects with high precision to optimize production processes.
Quality control in manufacturing
Surveillance and security: Besides facial recognition, computer vision is used to detect and track suspicious behavior, identify potential threats, and enhance overall security.
…
➡️ It is worth noting that numerous computer vision applications operate on the edge or in offline environments. However, since GPT-4 is solely accessible through a hosted API, its real-time performance may be limited in these circumstances.
🧨Exploring the Unknown Territories of the GPT-4’s Capabilities.
➡️ While GPT-4 is highly anticipated, it is important to note that OpenAI has yet to release an evaluation of GPT-4's performance on tasks such as object detection. There is much that is still unknown about its capabilities in various computer vision tasks. One area of interest is how well it will perform on quantitative tasks such as classification and object detection, which existing computer vision models have excelled at.
Counting is a task where the specificity required for accurate counts of objects may not be provided by generative language prediction, leaving it unclear how well GPT-4 will fare in this regard.
Another area to explore is localization, which hinges on the model architecture. If GPT-4 only featurizes images before inference, its localization capabilities may be limited.
Pose estimation: the precision with which GPT-4 can understand an individual’s pose remains to be seen. For example, understanding the depth of a pushup or the angle of rotation of one’s knees, which could be important for physical therapy applications.
➡️ The advent of GPT-4’s open domain knowledge presents an exciting opportunity to leverage its capabilities for a wide range of computer vision applications that were hitherto unachievable. To illustrate, Be My Eyes — an OpenAI partner, leveraging our multi-modal APIs, is developing an innovative application aimed at empowering low-sight individuals to gain a more comprehensive understanding of their surroundings. The capacity of GPT-4 for open-ended text predictions represents a paradigm shift in the flexibility of application development, omitting a portion of the business logic that is generally written around the predictions of structured models.
3. Production-Scale Deployment of GPT-4
➡️ In order for GPT-4 to be widely adopted in the industry, it is crucial that its predictions meet the required accuracy threshold for the given task. However, the successful adoption of GPT-4, and any future general multi-modal models, will ultimately depend on several key factors, including deployment costs, the latency of model inference, and user privacy/offline requirements.
GPT-4 Image Inference Latency: Since GPT-4 is hosted behind an inference API, response times may vary from a few seconds to several seconds, depending on input and output length. This limitation makes GPT-4 unsuitable for edge deployment latency scenarios.
GPT-4 offline inference ability: One key limitation of GPT-4 is that it is hosted behind an API, which means that enterprises must be willing to call an external API. Additionally, OpenAI has indicated that model inputs are not used for retraining, which may impact some use cases. For computer vision applications requiring offline inference, GPT-4 may not be a viable solution.
GPT-4 Image Inference Cost: One significant obstacle to adoption is the cost of image inference with GPT-4. For many tasks, it may be cost-prohibitive to invoke a GPT-4 inference, with the current API pricing at $0.03 per ~750 words in the prompt and $0.06 per ~750 words in the response. Image requests, in particular, may be challenging due to the high featurization costs and input length caps.
4. Summary
➡️ GPT-4’s general pre-trained models are set to transform the field of computer vision by offering a versatile and powerful solution to tasks reliant on web imagery. While it may struggle with specific use cases, the potential of GPT-4 is limitless, and it unlocks a wide range of new computer vision applications.
➡️ However, the successful adoption of GPT-4 is contingent on overcoming several challenges, including deployment costs, latency, and privacy/offline requirements. Despite these obstacles, GPT-4’s game-changing technology and a myriad of potential applications are sure to continue to drive interest and investment in the field of computer vision.
Thanks for reading everyone !!! 😊😊😊
Connect with me on LinkedIn: https://www.linkedin.com/in/ducliemdinh/.
Thank you very much, it's really interesting!